Building a Game Server in C++ #1: The Concept
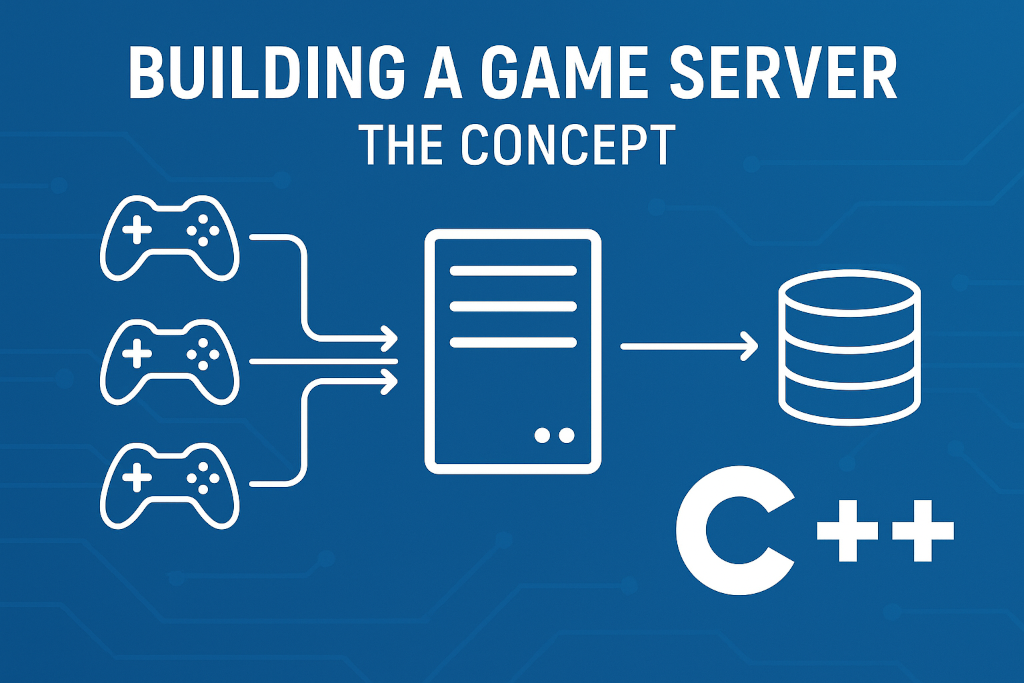
It’s been more than a decade since I last wrote any C++ code, and I’m feeling nostalgic about it. I have also always wanted to build a game server, so today I made the daring decision to scratch both itches.
I want the server to support all kinds of games: single player, two player, multiplayer, turn-based, real time… you name it! It should also be able to spawn different instances of the same game (aka worlds), so that the user can potentially select the game they want to play as well as the instance they want to join. Users should be able to enter a “lobby” state after connecting and authenticating. In that state, they should be able to browse the available game worlds and decide which to join, or create a new one from the game types available. So let’s start by defining the different states a user can traverse:

Apparently, the user can disconnect at any time, regardless of the state they’re in. That can occur either due to some kind of network issue or on purpose. The latter includes both a user deliberately disconnecting and the server “kicking” the user (ie due to timeout or abuse).
The authenticated state implies some kind of storage, where credentials are being kept. I’m pretty sure more storage requirements will emerge as I go, so I’m leaning towards utilizing a database connection. I will most probably use MySQL, since I am most familiar and fluent with it.
It also implies sessions. Which brings us to the question of what transfer protocol to use. UDP is the way to go for a game server, especially for real-time games, because it is stateless and fast. On the other hand, it is much easier to implement sessions with TCP. So the right path for my needs would be a hybrid model, where session-specific communication is being done via TCP and game data are exchanged via UDP.
I’d prefer those sessions to run as threads of their own. When a new TCP connection is made, a new thread will be created to handle the communication with the specific client, so that the server is able to continue listening for new connections. Furthermore, each session should have a distinct id. The new thread will receive the id as a parameter, along with the newly created connection. The thread’s first job is to send the session id to the client as a response to the connection. Lastly, the thread should have a way to communicate with the main thread, so it makes sense to pass a backlink reference as a third parameter.
Another aspect that comes to mind is the debug log. For now, I think I can settle with the old faithful stdout/stderr, although I will probably implement it as a backend object, which will give me some level for abstraction. Apart from the logger and the storage mentioned above, I’m sure I will eventually need other backends, but for now those should suffice.
So here’s a visual representation of the system with the assumptions I’ve made so far:

Apparently, the server will have to keep a list of session data. When a new connection is made, a new entry is appended, while when a client disconnects, the corresponding entry is discarded. Since this list will be effectively accessed by concurrent threads, it should be guarded with a mutex of sorts.
Speaking of session data, one thing that comes to mind is the coupling between the session and the corresponding UDP client address/port. Since, as mentioned above, the client receives its session id upon connection, it is expected to send it back via UDP. With this “handshake“, the server can detect the client address corresponding to the session id, and update the session list entry accordingly.
Apart from the handshake packet, communication via UDP should be done exclusively between the client and the game instance the user has joined. I want to leave this protocol as game-dependent as I can. The server will merely act as a UDP router between the game instance and its joined players.
Lastly, I want the server to be able to start with a set of parameters stored in a configuration file. Examples of such parameters would be the port to listen to and the database connection server/user/database/password. Absent or bogus parameters will fall back to defaults, while execution arguments (argv) will override the configuration file. A special kind of parameter would be the configuration file path itself, which will obviously be overridden only by an execution argument.
There are a bunch of other things that cross my mind, but I’d like to leave it at that for now. I think we have enough to get us started with some code, which I will cover in the next article.
One Comment